DT3 seemed to think these two pdf files (books digitized by Google) were duplicates:
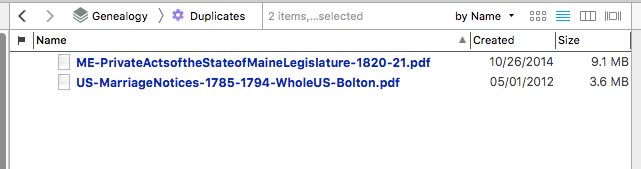
They have different names, contents, creation dates, and sizes. The one thing I could find that they had in common is that each had the standard Google Books “cover page”, which has a searchable text layer. The books themselves are not OCR-ed. Apparently, DT3 classified these documents as identical based solely on the (identical) content of that “cover page,” ignoring the size discrepancy (9.1 MB vs 3.6 MB).
When I deleted the cover page from both books, the duplicate designation disappeared. I would suggest that DT3’s file size threshold for duplicate recognition be adjusted.
1 Like
They are marked as duplicates because the only text content (the cover page) is a match. What if the content was close enough to warrant being flagged as a match, but the documents in question varied greatly in size due to other factors e.g. the OCR resolution. Should they not be flagged as duplicates, even though the content is otherwise a match?
Did you enable the stricter recognition of duplicates, see Preferences > General?
Mmm… no, I seemed to have missed that. I’ll need to go to a backup and retrieve copies of the files from before I deleted the cover pages to see if that preference solves the issue. Thanks.
Greg_Jones – I would rather such a set of “content” duplicates fail to be flagged as duplicates, than for true non-identical files to be erroneously flagged as duplicates. If there was a way to manually mark a set of files as not duplicates (when such is the case), then I could accept non-duplicates being occasionally identified as duplicates. But there is no way to turn off the duplicate flag in such a case.
