If it helps, I use Hazel to rename with dates. My approach is to have a separate rule for all my regular document types, and a fallback rule for anything that isn’t matched. Hazel is excellent at picking up all weird and wonderful date formats, even tricky ones like German train tickets that just have an unformatted date like 150420 written at the bottom.
Yes it means I have a few rules, but I also have a special “Rename” folder for that to keep them all in one place. Other Hazel rules (from scanner or downloads) drop it in here, this folder has a whole bunch of renaming rules and moves the file on when it’s done.
Thanks for this really interesting thread. I am struggeling with similar issues when trying to fully automate my workflows with hazel and DevonThink.
I appreciate the information provided here bur want to solve another problem in addition. How to automatically set the „date created“ or „date modified“ of the just scanned document and, even more important to me - in a batch job to all pdf documents already in DevonThink.
In my case all documents which I manually renamed have the name format
#yyyy-mm-dd.pdf
And this is the date I want a batch job to implemented to change the „date created“ or „date modified“. This allows me better sorting in DevonThink.
Anyone here who also plays around with dates and has a working solution?
Best Regards and stay healthy,
Uwe
Hi Mike,
hi enGeo,
would you mind sharing your rules to learn from them? Maybe via PN or Email?
BR,
Uwe (Munich)
Hi Uwe,
Very briefly, I have a sequence of folders that a file travels through, they have various rules
- Scan
- Backup -> Original scans backup, gets deleted after 30 days
- Rename -> Self explanatory
- Archive -> goes off to my NAS in YYYY-MM folders after a week
- Devonthink -> Import into DT
My download folder feeds into this as well. The reason for the sequence is because Hazel “follows” a file if I copy it - i.e. the next operation is on the resulting file. So I move it to backup and then copy it rather than the other way round.
I name most of my documents with date first, then any identifying info either with or without serial number
“2020-04-18 Hotel” for a hotel receipt.
“2020-04-18 1234 Train” for train tickets. My fallback rule uses “datecreated # date” if it finds a date, or else fallback 2 just uses “date #”
Some documents are grouped by type, such as bank statements, because I have my own DT group for each bank. So my Barclaycard statements end up as “Statement 2020-03” in my DT Barclaycard folder.
Here’s my rule for downloaded Barclaycard statements:

Statements are of course littered with dates, but my statement date is easy enough to pick out. In the header bit there are three dates:

The one I want is the second date in the PDF that is written out in full (PDF sequence is not always top to bottom). So I tell it to look for the second date

that is formatted in full
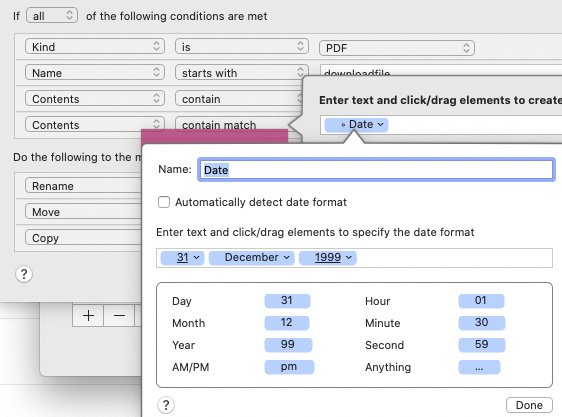
And Hazel lets me rename it using my own date format. For statements I want yyyy-mm:
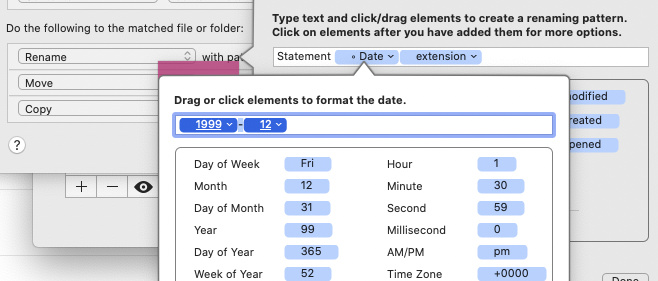
Hope that helps,
Mike
Hi Mike,
Thanks for the fast reply. I am using DT for a while now and had some similar approaches, however, since I had to change my ScanSnap Software to the new “Home” version I experience some issues in scanning to folders which are tracked by Hazel, as I have to manually confirm each and every scan. This info just BTW  need to figure out how to overcome this annoying pop-up windows for better automation.
need to figure out how to overcome this annoying pop-up windows for better automation.
Your multiple folder approach is interesting where Hazel can act in “stages” on the files to gain more flexibility on dealing with files. Thanks for sharing.
Best Regards,
Uwe
I have a very similar issue. When OCRing documents, I use the following smart rule:

It usually works OK, but on the following invoice:

It finds 01/31/2020 rather than 2/29/2020, which is the desired date. The “latest date on the document not later than today” would work great in this case as well.
Thanks,
Andy
What issues do you get? My old Epson scanner used to write files in such a way that Hazel would pick it up before it was finished. What I did there was initially to add a 30s delay using a script command but then I changed it to use a Hazel condition that the file must be at least 5 minutes old. I also have a ‘File it now’ folder with the same rules so if I’m in a hurry I could just drag and drop the files from my “Scanning” folder into there.
But with ScanSnap the temp file is handled differently, so my inbound scanning rule just checks for PDFs and it works fine (I have my 30 day backup folder if I discover a problem). I also do some manual scans as well and have had no issues.
The reason for multiple folders and rules is so my workflow steps are independent. They execute at different times, and if I change something I don’t have to change every single script. I can change my archiving strategy without touching anything else. The document-specific rules are in “Rename”. But then I also don’t follow my own system, some of my download rules do renaming too, see example above. It doesn’t make sense to split the renaming downloads as I don’t want all downloaded PDFs to go to DT, and if I already have a document-specific rule for downloads then I might as well do the renaming there too.
I do a few other bits on some documents too, like colour-tagging receipts. The system works reasonably well for me. It all fell to pieces when DevonThink 3 removed automator actions as I used those to file things into the right DT folders so I’m still trying to get the smart rules to work properly.
Try Scanning to File rather then Folder, the confirmation window then won’t show - https://share.getcloudapp.com/o0ugxbG0
Regards
Iain
I actually think scanning a letter as text file and Identify the first date in the content is very reliable.
I postet about this here.
I just changed the approach recently: I OCR to PDF which leads to „chaotic“ order of different areas of content and therefore searching for the first date in the pdf often results in the wrong date. This is why I OCR the same file to txt which leads to recognition from top to bottom. In this case the first date is usually the one the letter/ invoice/ etc. was written and therefore the one I am looking for. Once I have the txt I want to let Hazel (with a set of rules) search for the first date pattern in the txt and use that to rename the pdf. I had no time to fine-tune the set of rules yet but I successfully set up a proof of concept.
Here is AppleScript handler, which validates the date out of any string.
How it works:
IN:
You give it any string, supposing that the date there, if any, will be in the sequence: day, then month, then year. There may be any delimiters like “.”, “-” or “/” - doesn’t matter, figures for day and month may be one or two digits (like 03 or 3), year may be 2 or 4 digits.
OUT:
If this is a RIGHT date, script will return Date object (in the format of your system), else script will return the unchanged String. The “right date” means if such date can physically be in real calendar.
to get_date out of theString
set theFound to find text "^(?:(?:31(\\/|-|\\.)(?:0?[13578]|1[02]))\\1|(?:(?:29|30)(\\/|-|\\.)(?:0?[13-9]|1[0-2])\\2))(?:(?:1[6-9]|[2-9]\\d)?\\d{2})$|^(?:29(\\/|-|\\.)0?2\\3(?:(?:(?:1[6-9]|[2-9]\\d)?(?:0[48]|[2468][048]|[13579][26])|(?:(?:16|[2468][048]|[3579][26])00))))$|^(?:0?[1-9]|1\\d|2[0-8])(\\/|-|\\.)(?:(?:0?[1-9])|(?:1[0-2]))\\4(?:(?:1[6-9]|[2-9]\\d)?\\d{2})$" in theString with regexp and all occurrences
if theFound is not {} then
return date theString
else
return theString
end if
end get_date
To use this handler you’ll need a Satimage scripting addition
Happy scripting! 
1 Like
Thanks, I set up a set of Hazel rules to do this now. It works fine apart from one thing. I need a simple script that removes every subfolder and contents of a parent folder.