Hello,
I have many markdown notes coming from Obsidian which have
alias: some text.
I have a smart rule [1] which finds the necessary notes but the text replaced in their “Aliases” is the string \1 itself.
I have seen a few threads that use \1 and people seem happy with it.
Can you please tell me what I am doing wrong?
[1]
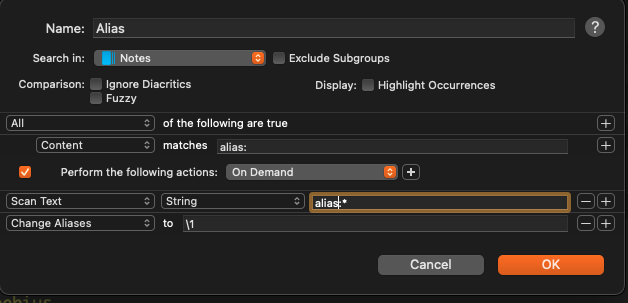
Use „regular expression“ instead of „string“ in the Scan text action. And provide a regular expression like alias:\s+(.*) to scan the text for.
Thank you @chrillek.
Your solution works if I move the “alias:…” string from the YALM front matter to the non-YALM text.
Re-reading the doc example p.247/248[1] I still don’t quite understand why String or RegExp: alias:* do not work. Just curious.
Is there a way for the rule to search all of the text, including the front matter?
[1]
Using the String parameter, Invoice * would capture 0012345 in a file named Invoice 0012345.. UsingtheDateparameter,* would capture the date in a file named 2020-01-01.
Regards,
Philippe
YAML is not rendered content so it’s not indexed, and yes, this is intentional.
You can enable a hidden preference to index the invisible content.
Select the Help > DEVONthink 3 Help > Documentation > Appendix > Hidden Preferences. Control-click the On link for IndexRawMarkdownSource. Then paste into the address bar in Safari, okaying opening DEVONthink.
You will need to do a File > Rebuild Database to index existing raw content. Do not interrupt the process and do not let the machine power down while it’s working.
Thank you @BLUEFROG
Regards,
Philippe
@BLUEFROG explained that: The front matter (YAML, in your case) is not considered to be part of the text by DT. So, Scan text does not scan that part. A script can handle that, though (or the hidden preference mentioned by @BLUEFROG).
You’re mixing up two concepts here
- DT “scan for string” uses DT’s own expressions and wildcards. In
alias: *, the * matches everything following the string "alias: ". And you use * to refer to this match in the replacement part.
- If you “scan for regular expression”, RE syntax is used. And there
alias: * would match the string “alias:” followed by any number of spaces (even zero). And you wouldn’t be able to use replace with this expression, since there’s no capturing group. So, alias:\s+(.*) as regular expression matches the string “alias:” followed by at least one space and captures everything following the space(s) in a group. In the replacement, you refer to that group with \1.
As to the example in the documentation: It’s probably a bit terse, but that is for @BLUEFROG to judge. Basically, the * is loaded with meaning depending on the parameter you select in the “Scan text”. “String” would match anything, “Date” would match a date and “Amount” would match an amount. It’s all a bit magical as dates (as amounts) come in many flavors. That’s why I mostly stick with REs because than I know what I’m doing 
Thanks @chrillek,
I will study scripts+RE for my future needs.
Regards,
Philippe
